

杂谈ELK体系组件
杂谈ELK体系组件
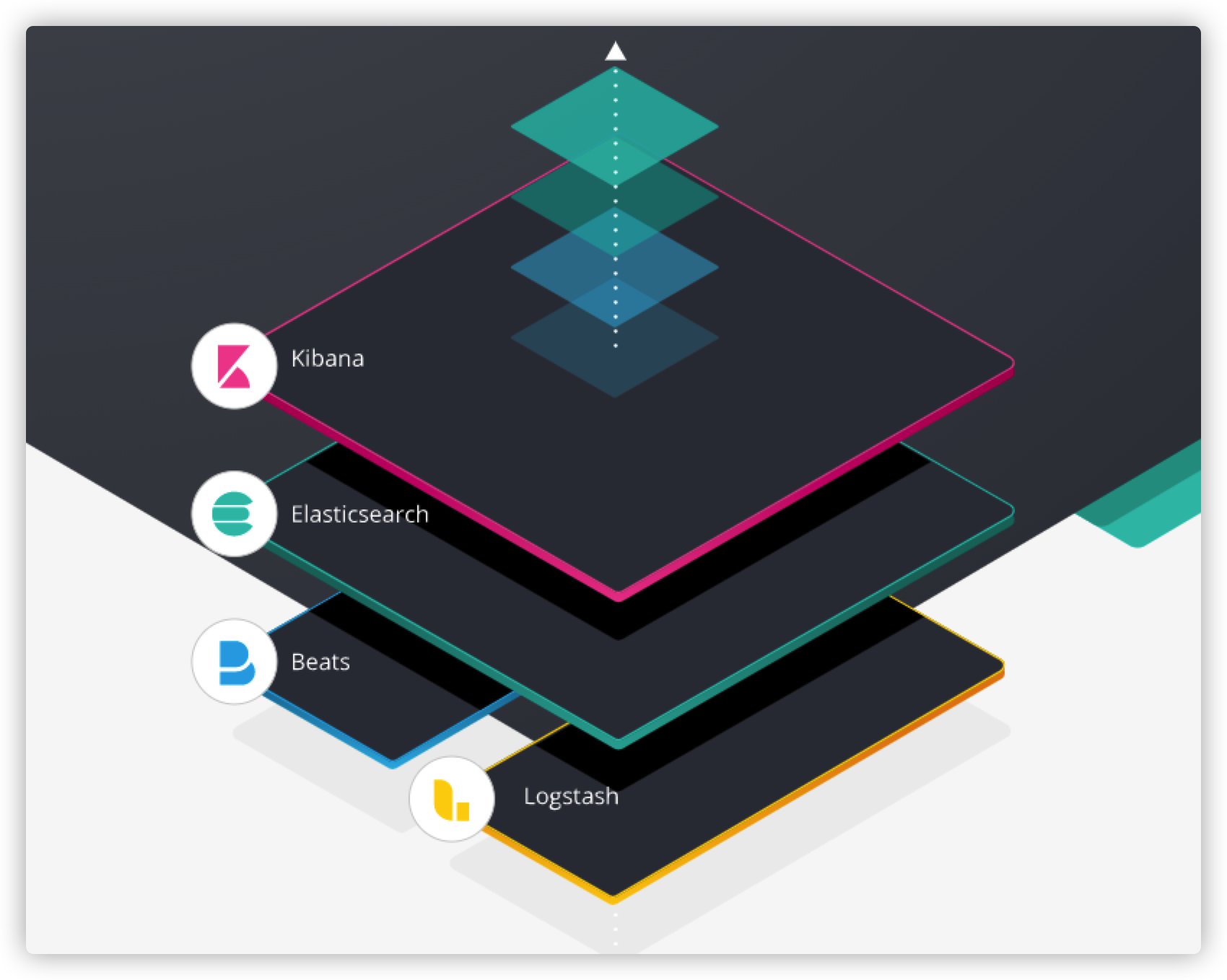
1、ELK组件介绍
1.1、什么是ELK?
我们目前工作中常常说起elk,用到elk日志系统进行线上问题跟踪排查,实际上elk是一个以elasticsearch搜索引擎为中心,以beats或logstash为采集源头,kibana作为交互展示的体系框架。开源免费,不仅仅可以用到日志的存储和分析上,还可以用到实际的业务数据上。
1.2、Elasticsearch

开源,分布式,RESTful协议 的全文本搜索和分析引擎,支持集群部署,大数据量处理,数据分片于 2010 年首次发布
- 以json格式存储文档内容
- 支持多种类型的搜索(结构化数据、非结构化数据、地理位置、指标)
- 高扩展性,支持集群部署,支持容灾,自动上线下线集群节点
- 支持存储海量数据,通过水平扩容,数据分片,支持大规模数据的存储和分析
- 通过数据分词,建立全文检索倒排索引,适用于各种复杂条件的搜索查询
1.3、Logstash

Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
- 支持多种数据输入源,数据格式,使用起来轻松方便,比如常见的数据源: beats、kafka、rabbitmq、redis、syslog 等等,数据格式既可以是json,也可以是文本等,详见https://www.elastic.co/guide/en/logstash/current/input-plugins.html
- 拥有强大的插件能力,目前已有200多个插件,通过插件可以对数据格式进行转换,数据过滤等,只保留自己需要的数据,比如把非json结构的文档转成json,把IP解析成地理坐标,移除一些不需要关心的数据等等
- 支持多种数据输出源,首推elasticsearch作为数据输出源,还可以输入到zabbix、redis、kafka、http等,详细见https://www.elastic.co/guide/en/logstash/current/output-plugins.html

1.4、Kibana
Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化

- 对elasticsarch中的数据进行筛选过滤查询,方便的日志内容浏览
- 创建图标,聚合内容,表格,提供各种图形展示和聚合分析能力
- APM/地理位置/DevTool等等功能
1.5、Beats
轻量级的数据采集器

- Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器
- 提供多种信息采集的beats应用
- 轻量,运行简单,开箱即用
2、ELK组件的部署
推荐使用docker 进行部署,部署的组件应具有相同的版本
也可以下载压缩包,解压了进行运行
2.1、Elasticsearch
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.16.2
docker run -d --privileged --restart=unless-stopped -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.16.2
集群部署配置:
#节点名称
node.name=es03
#集群名称
cluster.name=es-docker-cluster
#集群其他节点
discovery.seed_hosts=es01,es02
#集群master节点
cluster.initial_master_nodes=es01,es02,es03
节点类型:
- master: 有资格被选作为主节点,控制整个集群
- data: 该节点保存数据和执行数据相关的操作,如增删改查,搜索,和聚合
- 客户端节点:如果既不是master也不是data节点,则为客户端节点,只接收请求,转发到其他节点去处理
- 一个节点既可以是master节点和data节点,也可以只是其中一个类型
2.2、Beats
FileBeats
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/filebeat-7.16.2-linux-x86_64.tar.gz
tar xzvf filebeat-7.16.2-linux-x86_64.tar.gz
./filebeat -e
配置文件:
filebeat.inputs:
- type: filestream
# Change to true to enable this input configuration.
enabled: false
# Paths that should be crawled and fetched. Glob based paths.
include_lines: ['^ERROR','^WARN']
exclude_lines: ['^DBG']
paths:
- xxx/logs/*.log
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
2.3、Logstash
下载解压
https://artifacts.elastic.co/downloads/logstash/logstash-7.16.2-linux-x86_64.tar.gz
tar -zxf logstash-7.16.2-linux-x86_64.tar.gz
测试一个pipeline
#first-pipeline.conf
input {
stdin {}
}
# The filter part of this file is commented out to indicate that it is
# optional.
# filter {
#
# }
output {
stdout { codec => rubydebug }
}
#运行
bin/logstash -f first-pipeline.conf --config.reload.automatic
2.4、Kibana
docker pull docker.elastic.co/kibana/kibana:7.16.2
docker run -d --name kibana7.16.2 -p 5601:5601 -v /home/tuhu/kibana_local:/usr/share/kibana/config kibana:7.16.2
配置:
server.port: 5601
server.host: "0.0.0.0"
# es集群的机器地址
elasticsearch.hosts: ["http://127.0.0.1:9200"]
3、ELK组件的使用
3.1、Elasticsearch
3.1.1、数据类型
- Number
- Keyword 不能分词的字符串
- Text 会分词的字符串
- Date
- Geo
- Boolean
- Array
- Nested
3.1.2、mapping (文档结构描述)
{
"settings":{
"analysis":{
"analyzer":{
"my_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":[
"lowercase"
]
},
"my_stop_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":[
"lowercase",
"english_stop"
]
}
},
"filter":{
"english_stop":{
"type":"stop",
"stopwords":"_english_"
}
}
}
},
"mappings":{
"properties":{
"title": {
"type":"text",
"analyzer":"my_analyzer",
"search_analyzer":"my_stop_analyzer"
}
}
}
}
- analyzer 分析器,可以对文本进行分词处理
- tokenizer 分词器,比如IK中文分词器,拼音分词器等等,可以集成分词插件
- filter 分词过滤器,可以在分词的同时,对词进行处理,比如转小写
- properties 索引文档的属性定义
- title 字段名称
- analyzer 存储使用的分析器,比如存储使用ik_max_word
- search_analyzer 搜索时使用的分析器,比如搜索使用ik_smart_word
3.1.3、分词、模糊查询
一句话到es里面大概分成了什么样呢?
比如:
养车用途虎,一点不辛苦
POST _analyze
{
"analyzer": "ik_max_word",
"text": "养车用途虎,一点不辛苦"
}
分词结果:
{
"tokens" : [
{
"token" : "养车",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "用途",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "途虎",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "一点",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "一",
"start_offset" : 6,
"end_offset" : 7,
"type" : "TYPE_CNUM",
"position" : 4
},
{
"token" : "点",
"start_offset" : 7,
"end_offset" : 8,
"type" : "COUNT",
"position" : 5
},
{
"token" : "不",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 6
},
{
"token" : "辛苦",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 7
}
]
}
es会根据分词的结果在内部建立倒排索引树
模糊查询如何匹配的?
比如:我们搜 途虎
搜索引擎也要对传入的参数先进行分词,通过分词之后再根据匹配条件进行匹配
POST _analyze
{
"analyzer": "ik_max_word",
"text": "途虎"
}
{
"tokens" : [
{
"token" : "途虎",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
}
]
}
传入的分词后的结果可以在已经存储的倒排索引中找到,我们就可以搜索到这个文档数据
3.1.4、常用的es查询条件
- term/terms 精确匹配,==关系
{
"query": {
"terms": {
"code": [
"920064001"
]
}
}
}
- range 范围匹配
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
- match 模糊查询,通过分词进行匹配
- match_phare 模糊查询,通过分词进行匹配,并且分词的顺序位置都要匹配和保持一致
{
"query":{
"match":{
"content.ik_smart_analyzer":"系统编程"
}
}
}
- bool 对于多个查询条件,可以使用bool进行组合
- should 多个条件或的关系
- must 多个条件且的关系
{
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"term": {
"parentCodeArray": {
"value": {{code}}
}
}
},
{
"term": {
"code": {
"value": {{code}}
}
}
}
]
}
},
{
"term": {
"status": {{status}}
}
}
]
}
},
"sort" : [
{ "level" : "asc"},
{ "countryCode" : "asc" },
{ "pinyin" : "asc" },
"_score"
],
"size": 20,
"from": 0
}
3.2、Logstash
管道(pipeline):logstash核心是可以启动一个一个的管道,每个管道独立运行,都包含input/filter/output,而管道输出的数据也可以进入到另一个管道中再进行加工,满足各种数据处理场景

多个pipeline配置文件可以在pipelines.yml 文件中进行配置
# config/pipelines.yml
- pipeline.id: upstream
config.string: input { stdin {} } output { pipeline { send_to => [myVirtualAddress] } }
- pipeline.id: downstream
config.string: input { pipeline { address => myVirtualAddress } }
单个pipeline的配置,每个都是独立的文件配置
# This is a comment. You should use comments to describe
# parts of your configuration.
input {
...
}
filter {
...
}
output {
...
}
input:
- beats
input {
beats {
id => "my_plugin_id"
port => 5044
}
}
- kafka
input {
kafka {
id => "my_plugin_id"
bootstrap_servers => "host1:port1,host2:port2"
client_id => "logstash"
consumer_threads => 1
topics => ["logstash-test"]
}
}
- http
input {
http {
id => "my_plugin_id"
host => "0.0.0.0"
port => 9090
max_pending_requests => 200
}
}
filter
- dissect(对特定规则的非结构数据解析成结构数据)
filter {
dissect {
mapping => {
"message" => "%{ts} %{+ts} %{+ts} %{src} %{} %{prog}[%{pid}]: %{msg}"
},
# 转换类型
convert_datatype => {
"cpu" => "float"
"code" => "int"
}
}
}
- grok(应对复杂场景的非结构数据解析,速度比dissect稍慢)
# 55.3.244.1 GET /index.html 15824 0.043
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
# Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<[email protected]>
filter {
grok {
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}
- drop
filter {
if [loglevel] == "debug" {
drop { }
}
}
- json
filter {
json {
source => "message"
}
}
- mutate
filter {
mutate {
split => { "hostname" => "." }
add_field => { "shortHostname" => "%{[hostname][0]}" }
}
mutate {
rename => {"shortHostname" => "hostname"}
}
mutate {
convert => {
"fieldname" => "integer"
"booleanfield" => "boolean"
}
}
mutate {
join => { "fieldname" => "," }
}
mutate {
lowercase => [ "fieldname" ]
}
}
- prune
filter {
prune {
blacklist_names => [ "method", "(referrer|status)", "${some}_field" ]
}
prune {
whitelist_names => [ "method", "(referrer|status)", "${some}_field" ]
}
prune {
blacklist_values => [ "uripath", "/index.php",
"method", "(HEAD|OPTIONS)",
"status", "^[^2]" ]
}
prune {
whitelist_values => [ "uripath", "/index.php",
"method", "(GET|POST)",
"status", "^[^2]" ]
}
}
3.3、Kibana
3.3.1、Index patterns
在kibana中,如果想要查询es的索引数据,需要先新增index pattern


3.3.2、查看索引内容

一条索引文档中会有很多字段,我们可以让其单独显示出来,或者进行筛选过滤

4、Demo
4.1、Demo1
启动一个java应用,将日志写到本地文件中,然后通过beat进行采集,在logstash中进行一些处理,然后输入到elasticsearch中,最后再kibana中进行查询
4.1.1、java应用
public class TestController {
@GetMapping("randomLog")
public String randomLog() {
int no = (int) (1000 + (9999 * Math.random()));
if (no < 5000) {
log.error("这是一个错误的日志信息,random={}", no);
} else {
log.info("这是一条随机测试日志,random={}", no);
}
return "success";
}
}
在properties中配置日志打印到文件中
logging.file.path=logs/
启动应用
java -jar docker-test-0.0.1-SNAPSHOT.jar
4.1.2、filebeat读取配置文件
filebeat.inputs:
- type: filestream
# Change to true to enable this input configuration.
enabled: false
# Paths that should be crawled and fetched. Glob based paths.
include_lines: ['^ERROR','^WARN']
exclude_lines: ['^DBG']
paths:
- /home/tuhu/work/logs/*.log
fields:
appId: docker-test
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
4.1.3、logstash 默认配置
input {
beats {
id => "test_pipeline"
port => 5044
}
}
filter {
...
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}
4.1.4、在kibana中查看日志

可以看到已经能查询到,但是message中仍包含很多可筛选的信息没办法筛选出来,比如INFO字段
4.1.5、在logstash中对日志进行过滤
input {
beats {
id => "test_pipeline"
port => "5044"
}
}
# The filter part of this file is commented out to indicate that it is
# optional.
filter {
# 将字段分割出来为结构化的数据
dissect {
mapping => {
"message" => "%{logDate} %{logTime} %{level} %{} --- %{} %{logger} : %{msg}"
}
}
# 把不需要展示的字段过滤掉
prune {
blacklist_names => [ "message","agent" ]
}
}
output {
elasticsearch {
hosts => [ "localhost:9200" ]
}
}
再次到kibana查询日志就可以发现我们的日志已经截取出来了

4.1、Demo2
1、如果不将日志打印到本地文件的,那是如何上传到elk的系统中去的呢?
2、message中的内容过少,如果还想增加一些其他业务上的数据字段怎么增加呢?比如堆栈信息,appId,requestId 等等
